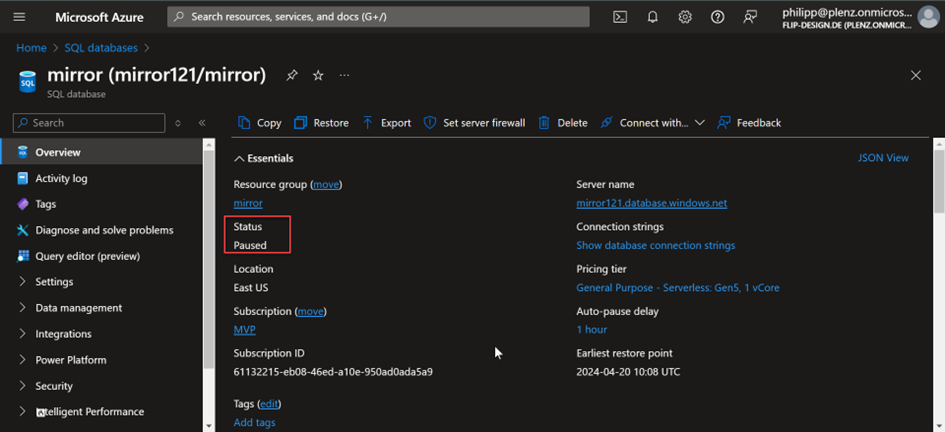
The ability to mirror data is not new if you have dealt with SQL Server. The ability to mirror databases was added a long time ago. Setting this up was much more difficult, and it also required a costly enterprise license. Now there is a preview function for mirroring databases in Power BI or Fabric. The data is stored in OneLake and can be used from there. Of course, the data is provided via an SQL endpoint and can also be read and analyzed in Power BI. This function is very useful if the database is constantly being written and read. This means that users are not disturbed by the person analyzing the data when editing it. The creation of mirrored databases is currently limited to Azure SQL, Cosmos and Snowflake databases. However, I think that this will expand in the next few weeks or months. In this entry I would like to show how the database is mirrored and what else needs to be taken into account. First of all, I created an Azure database that pauses when not in use. Serverless, so the database costs significantly less money to use. However, if the database is mirrored, the database is constantly accessed to determine whether data has changed. This means that the database is always in active mode and is therefore also cost-intensive.
To achieve this feature, Fabric must be enabled.
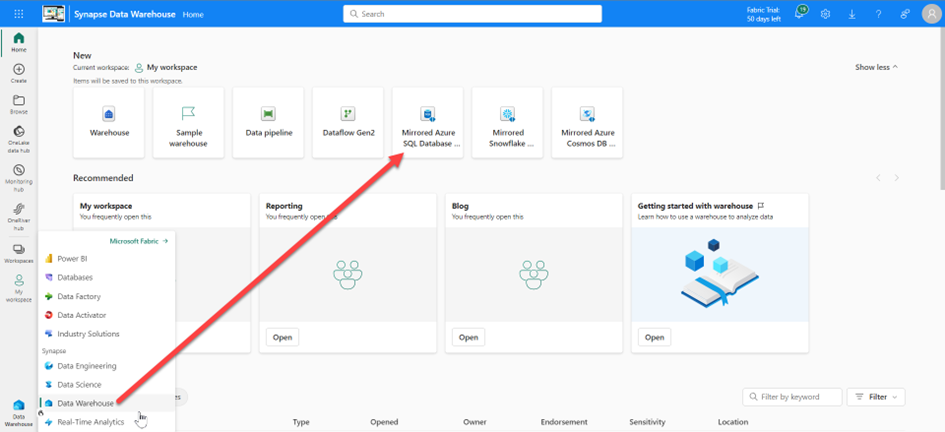
However, in order for the function to be used, system-assigned managed identity must be activated on the database. It does not matter whether SQL-based authentication is used.
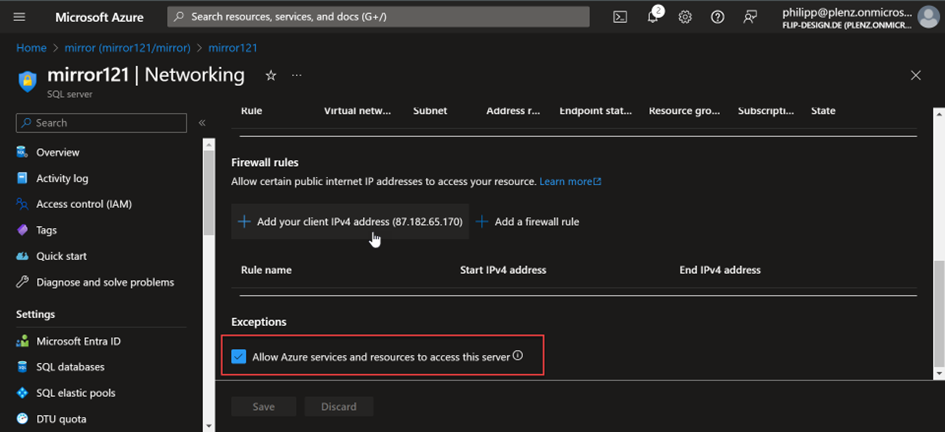
Further information can be found here:
https://community.fabric.microsoft.com/t5/General-Discussion/Mirroring-in-Fabric-Managed-Identity-error/td-p/3847842 After the mirroring name has been assigned, a connection to the database is established:
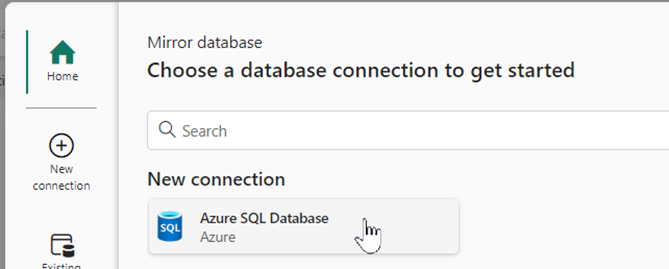
For this demonstration, I also use SQL-based authentication. The data for this can be read from the Azure platform.
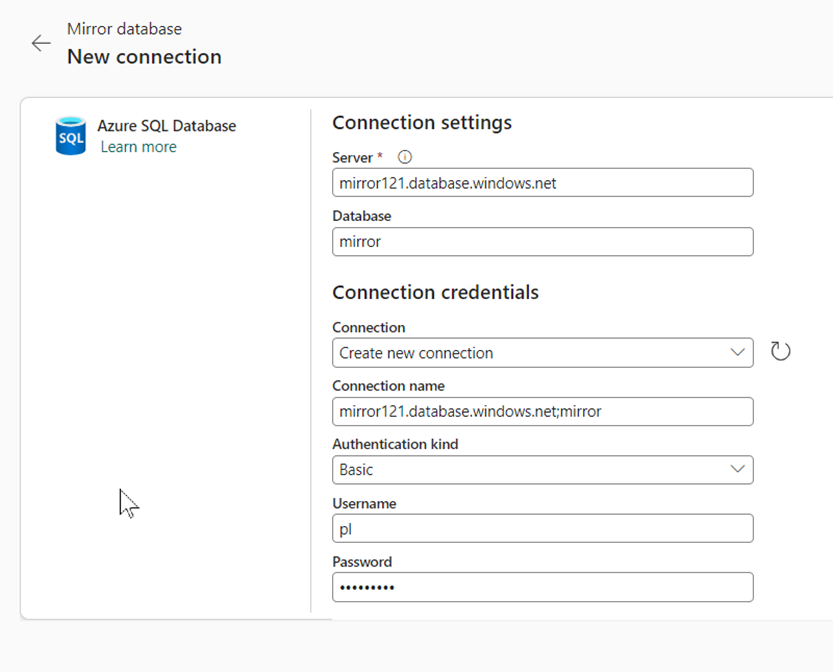
After confirming this window, you can select either individual tables or all of them.
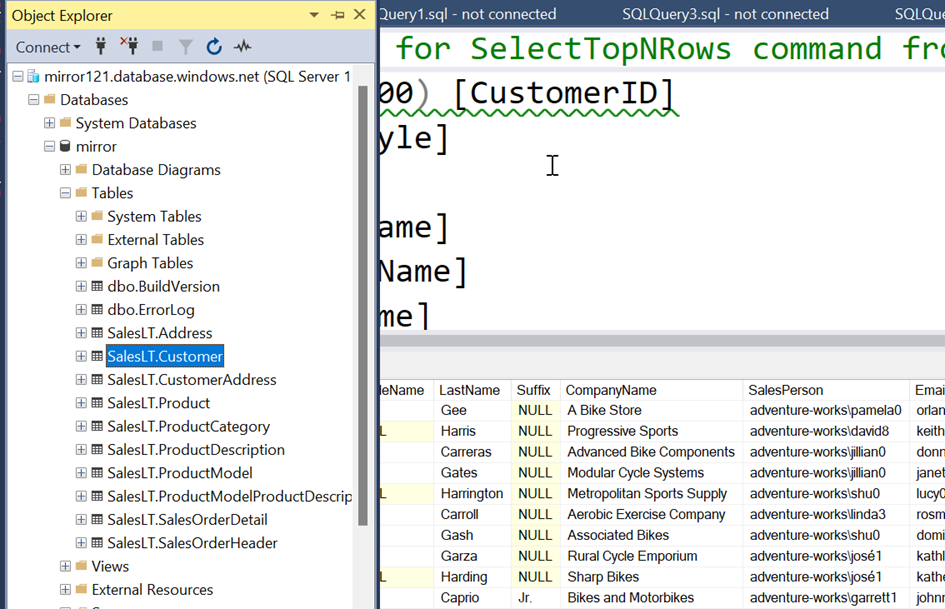
After confirming, you have to wait a moment for the mirroring to start.
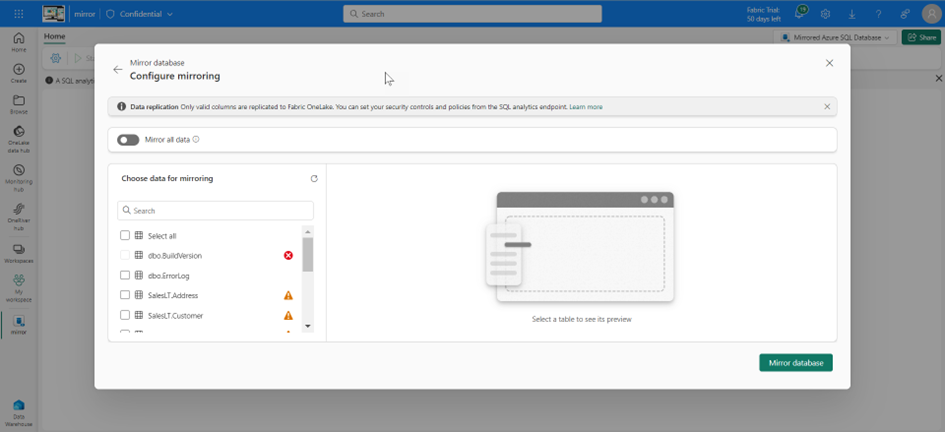
However, it should be noted that some tables provide information about which columns cannot be mirrored. The information can be found behind the symbols.
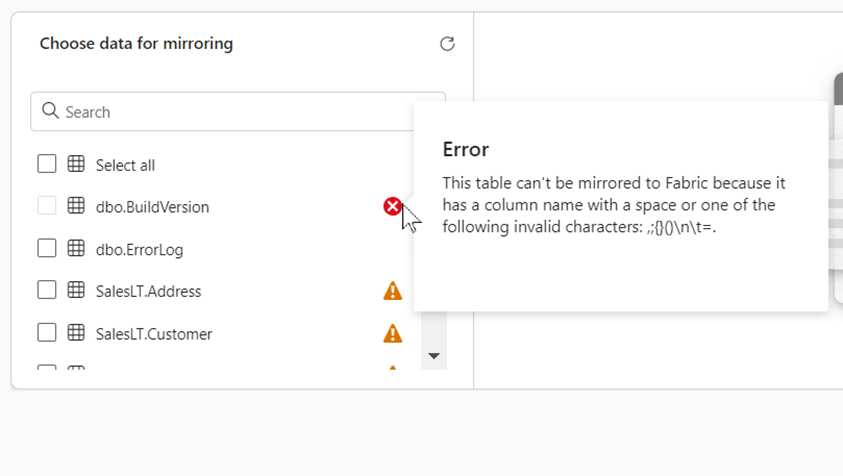
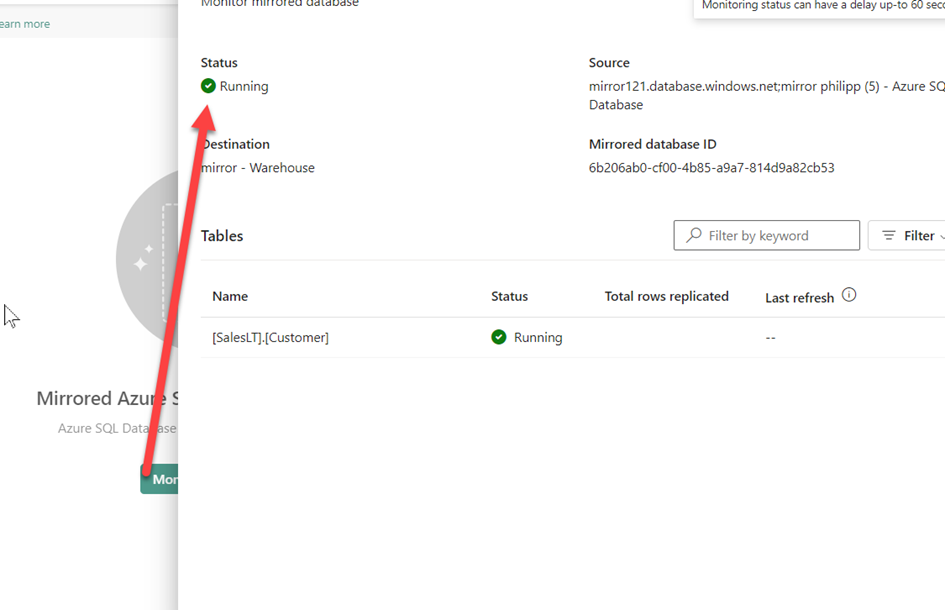
After confirming this window, the mirroring starts:
the objects are created with the workspace where you were originally located.
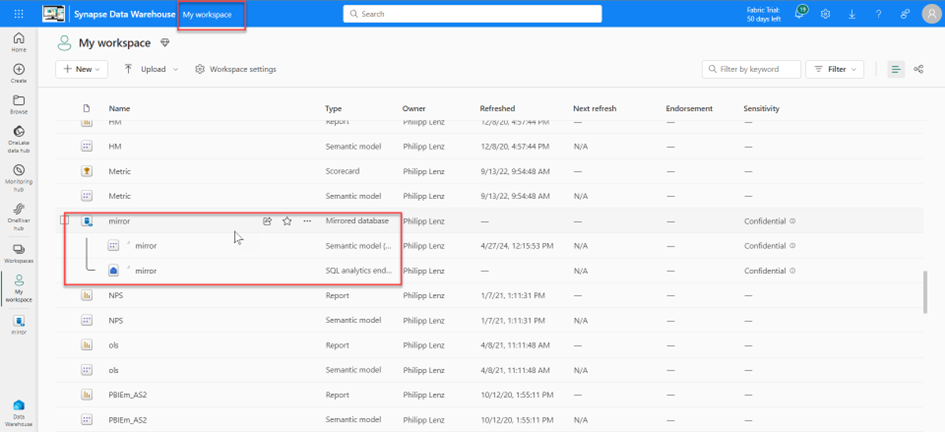
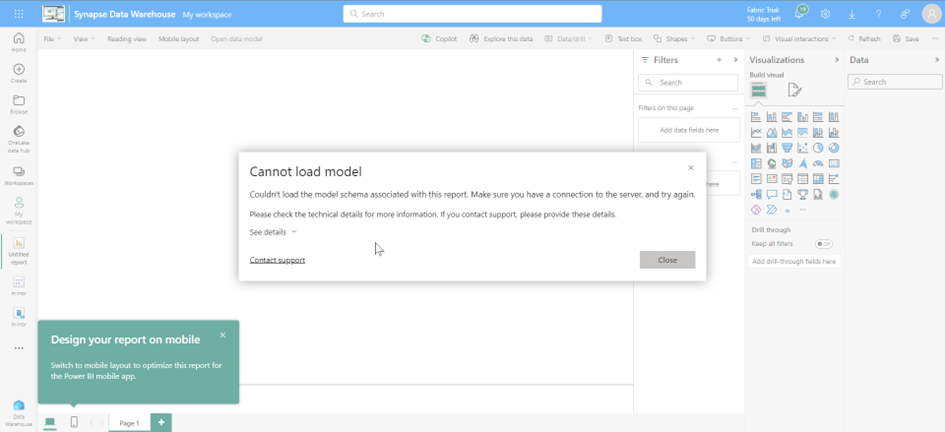
Even though a semantic model has been created here, it is not usable.
In the properties of the analytical database, the connection point with the SQL database can be copied.
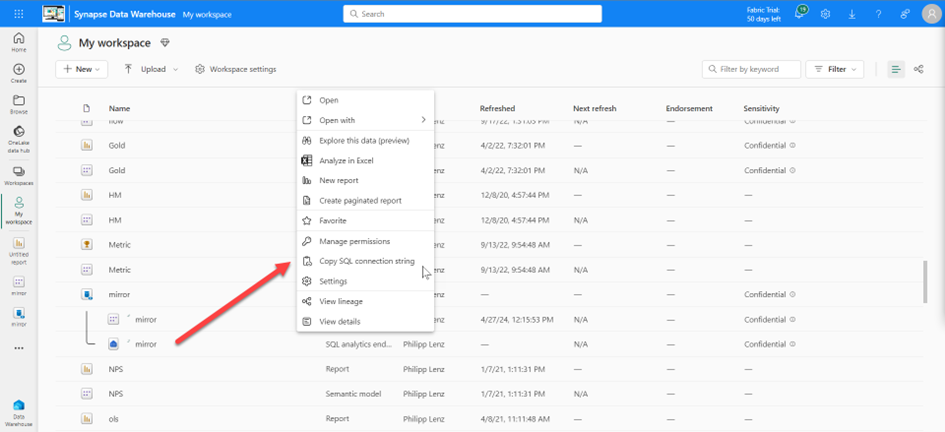
A connection can also be established with this database, and the mirrored objects can be found there and queried. It is not possible to change these objects by entering new data or changing the structure.
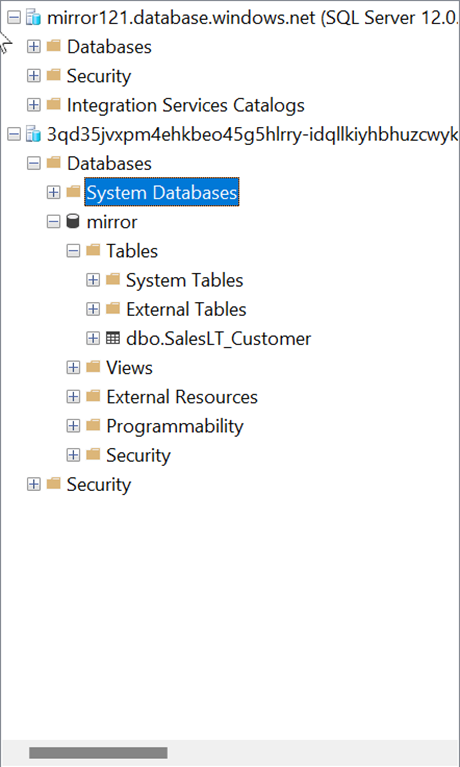
A connection to the SQL database can also be established from the Power BI Desktop side:
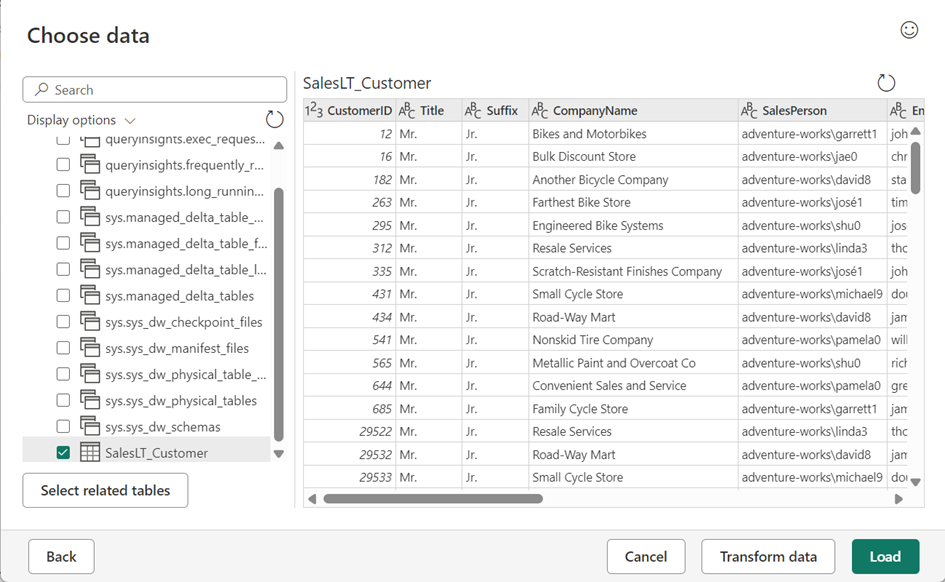
When you query the table, you can see the data it contains from the source database.
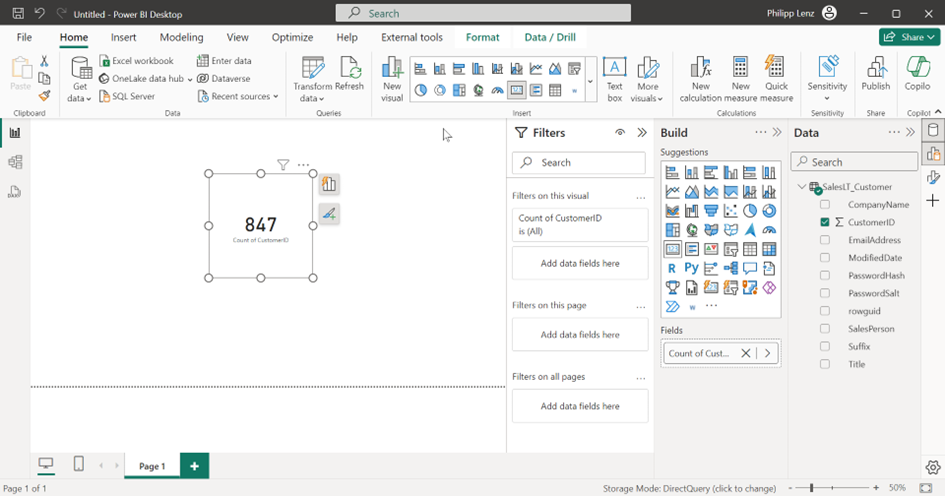
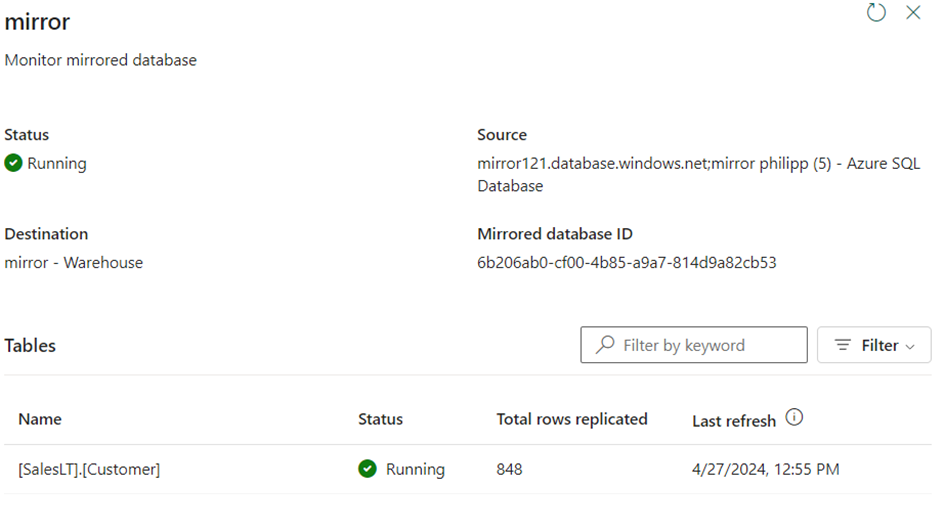
If a record is deleted or added in the source database, the mirroring can be monitored. In this example, I have deleted a row. However, the rows are not displayed correctly.
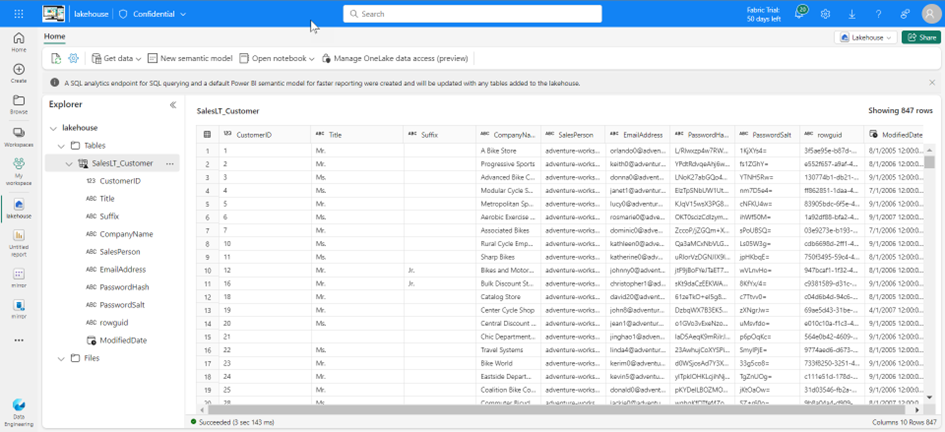
The data can also be processed with the Lakehouse in Fabric, as it is located in OneLake