„Translytical“ is a term used in data management and analytics that combines „transactional“ and „analytical“ processing.
source: ChatGPT
This new functionality within Power BI offers the ability to write, modify, and delete data within the database. This functionality is currently in preview. It also currently only supports data sources available within Fabric. Additionally, it only requires the Python programming language.
First, this functionality must be enabled in the Admin Portal. This may seem unnecessary at first, but the functions can only be created via the service.Diese Funktionalität wird generell aktiviert, d. h. sie kann nicht nur einzelnen Benutzergruppen zur Verfügung gestellt werden.
Nun kann man innerhalb eines Arbeitsbereiches, der selbstverständlich mit einer Fabric Kapazität verbunden sein muss, die sogenannten UDF’s erstellen.
Once this has been created, a new function can be stored in this container.
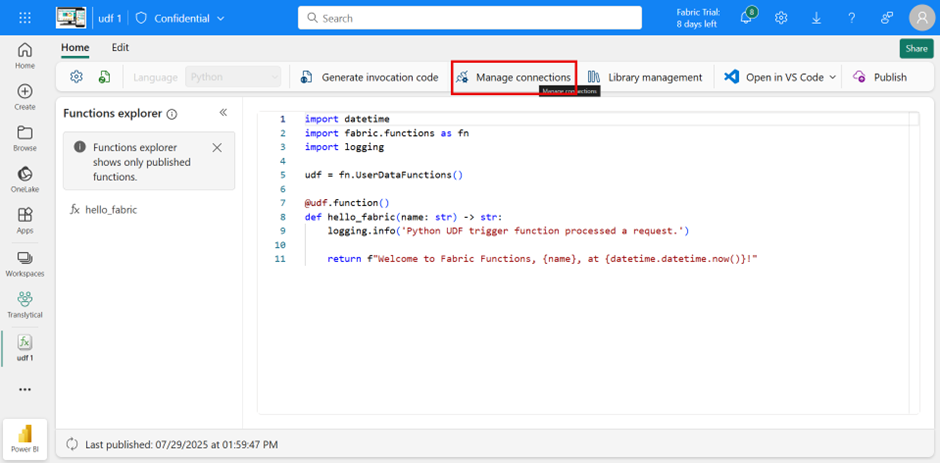
To write or modify corresponding data, a corresponding data source must be configured. This is done using the following switch:
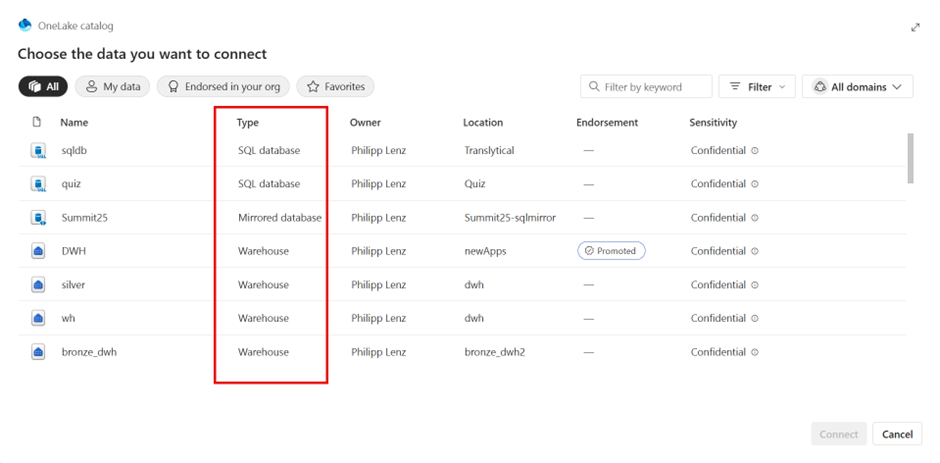
You can then select a data source. This screenshot shows the selection of supported data sources. It’s important that the data source is located within Fabric and that a SQL endpoint is offered. Then you can select it here.

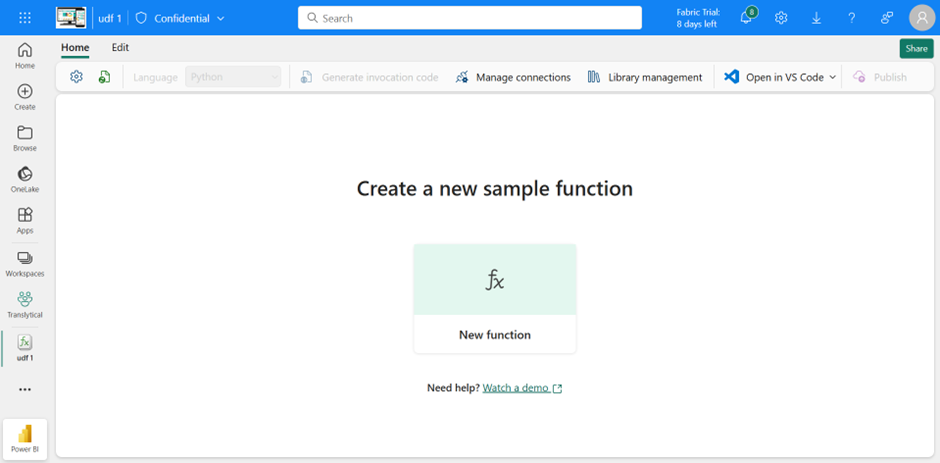
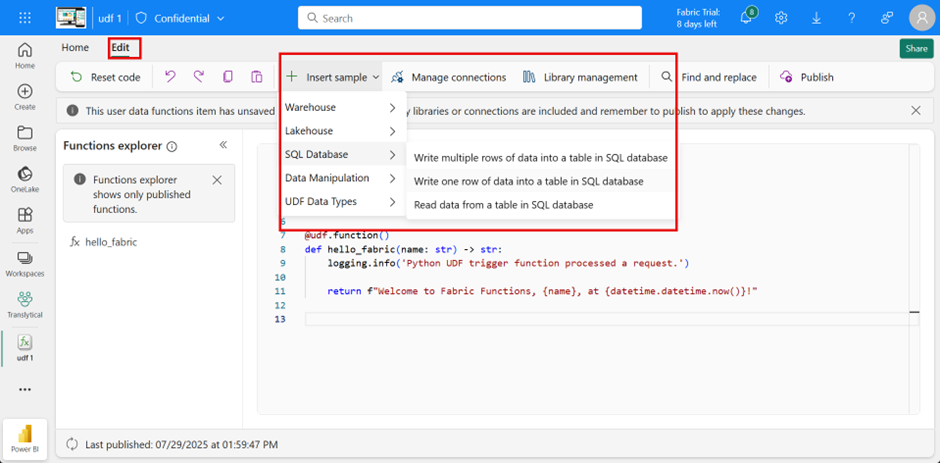
I’m not really a Python expert myself, but when you’re in the function’s edit mode, you can select appropriate templates.
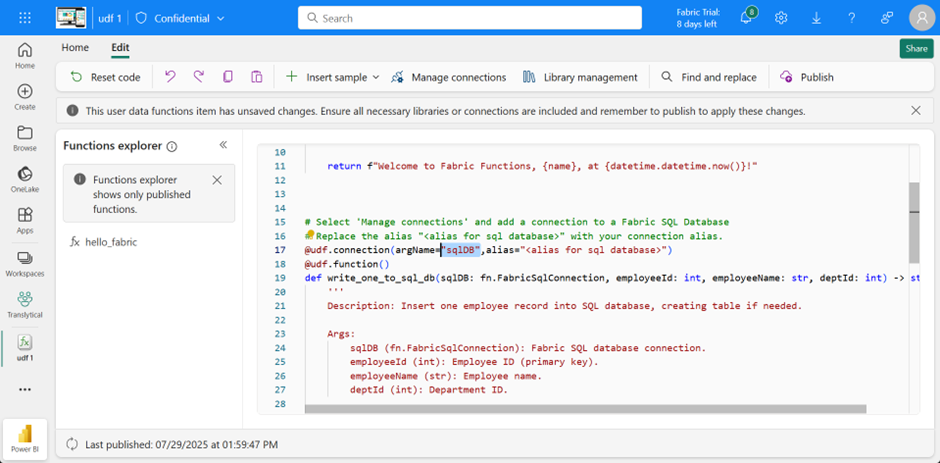
Once the connection has been established, it must be passed to the function. In this example, I’m using only one. Of course, several can be used for different use cases. Here, the data source is simply sqldb, so no adjustments are necessary.
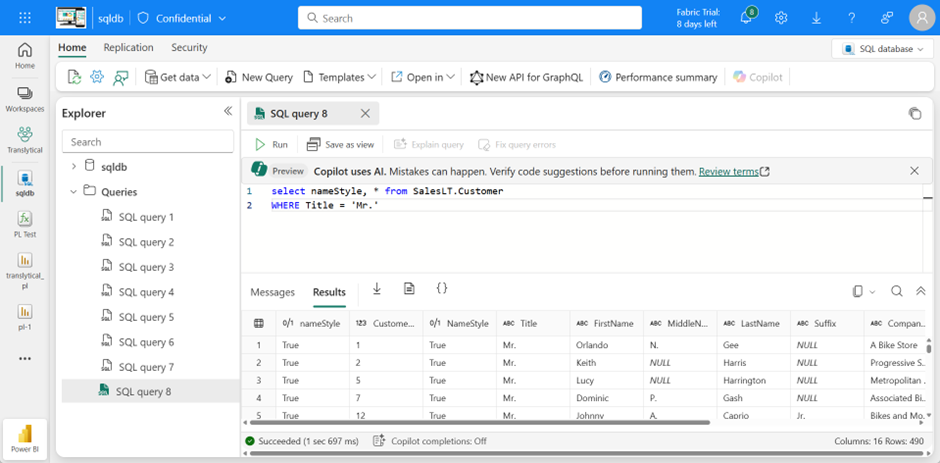
As you can see here, any SQL query supported by the source can be passed.
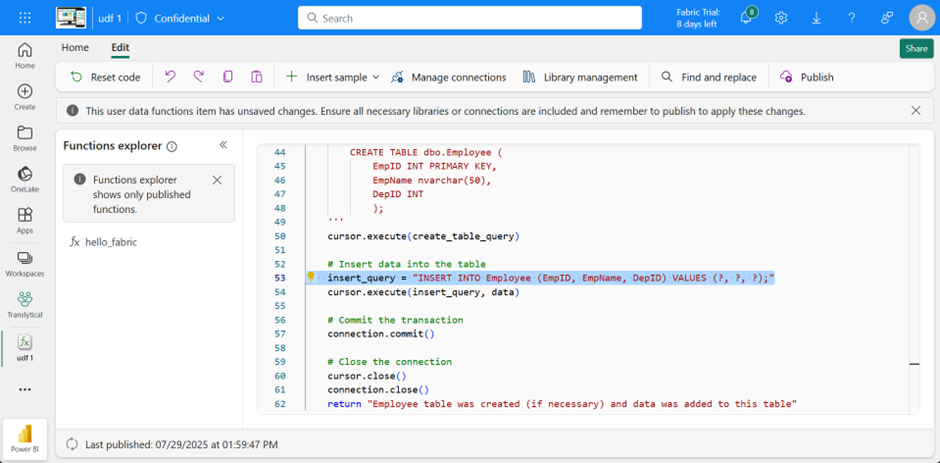
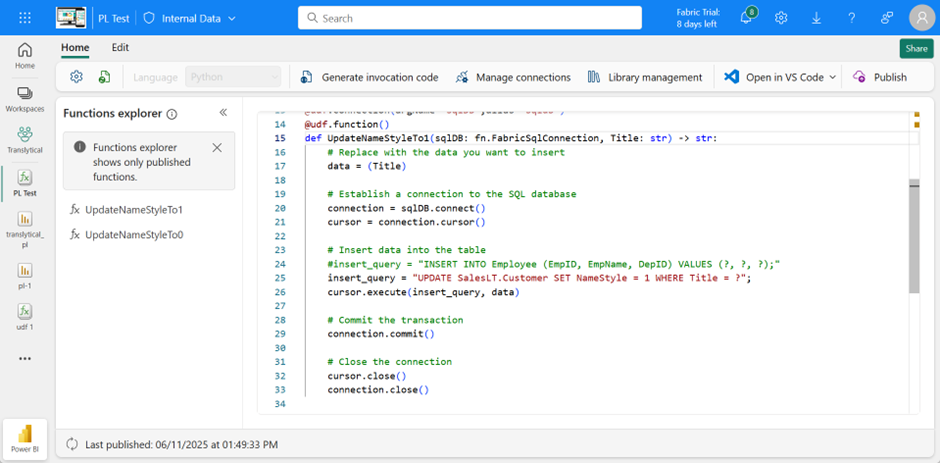
Here’s a complete example:
In this example, I’ve configured two separate functions within the function, each of which accepts a parameter and uses it for filtering in the Where condition. This simply updates the corresponding data.
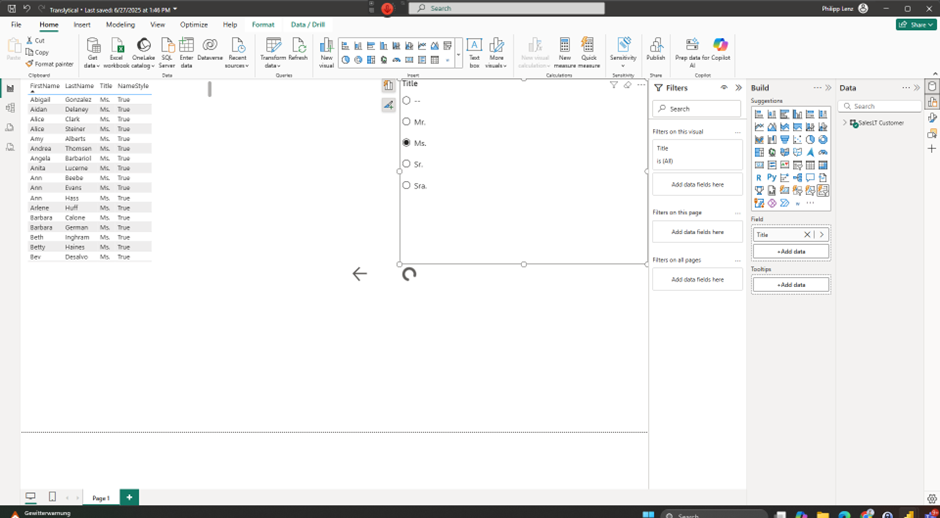
I then created the report within Power BI Desktop. It’s important to establish a live connection. Technically, this isn’t absolutely necessary, meaning data can also be imported, but to ensure the results are visible promptly, this is better used for this purpose. To implement filtering with slicers, the new one must be used.
To trigger the functions, I implemented two buttons and selected them via the actions and used the parameter from the slicer.
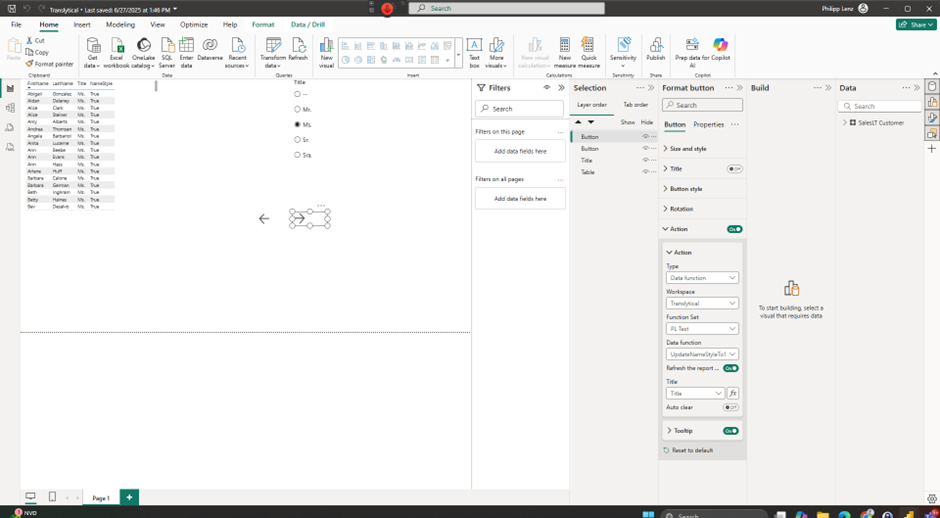
Even though a Direct Query connection was used here, the updates to the database aren’t visible in the report until approximately 30 seconds later. However, the database update was made immediately. The reason for this is that the semantic model caches the data and doesn’t immediately make the changes visible. Unfortunately, changing the configuration on the service doesn’t make any difference.