I was very happy that this feature finally went into public preview! I enjoy developing with UDFs, especially in the SQL Server environment. I had already needed this feature for the following blog post:
https://www.flip-design.de/?p=1447
This follows the concept of passing multiple values separated by a delimiter. So, similar to a one-dimensional array.
So I set about implementing this feature within Power BI.
Code
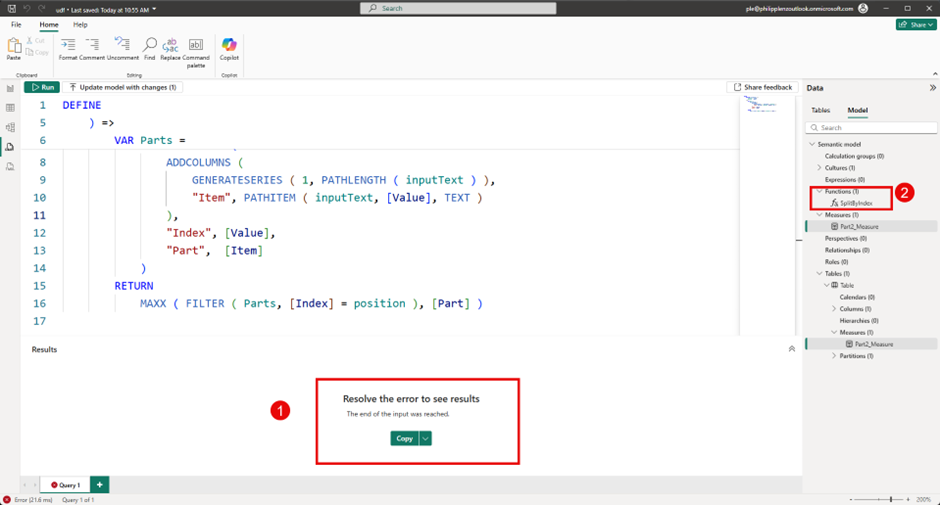
DEFINE
FUNCTION SplitByIndex = (
inputText : STRING,
position : INT64
) =>
VAR Parts =
SELECTCOLUMNS (
ADDCOLUMNS (
GENERATESERIES ( 1, PATHLENGTH ( inputText ) ),
"Item", PATHITEM ( inputText, [Value], TEXT )
),
"Index", [Value],
"Part", [Item]
)
RETURN
MAXX ( FILTER ( Parts, [Index] = position ), [Part] )
It’s important to note that, as we highlighted under 1, an error sometimes occurs during creation. The function should still be created, so this message can be ignored. To subsequently change this function, you should switch to the TMDL mask, where you won’t receive these errors.
As a next step, I developed a measure that calls this function. Instead of manually passing the list, in a real-world scenario, at least as I wrote it, you would access the variable CUSTOMDATA(), which then returns the corresponding list. This way, you only create one measure for each segment, which you can then use in the DAX code.
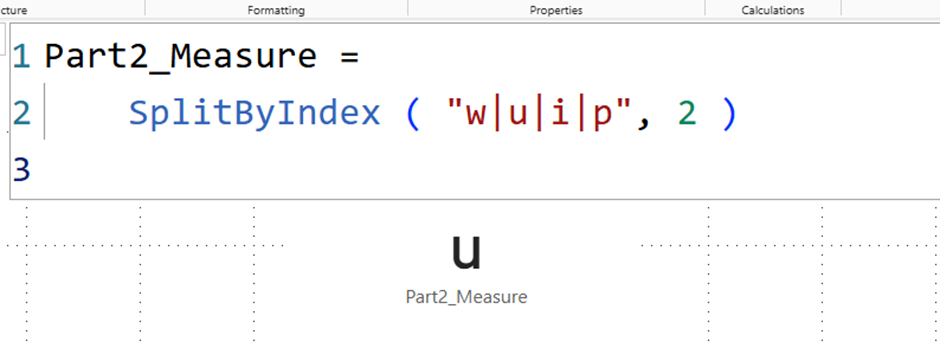
Part2_Measure =
SplitByIndex ( "w|u|i|p", 2 )Further information can also be found here:
https://powerbi.microsoft.com/en-us/blog/dax-udfs-preview-code-once-reuse-everywhere/