In this post I will cover the feature inside Power BI Desktop to set a row identifier for a table. But firstly, let me explain the scenario.
Sometimes you have inside your data some names, but there are not the same and you need to divide it by a key. So, imagine you have a sales table for your customers. Mostly, you will have the same duplicate names, but most tuples with the same names, are not pointing to the same customers. But no worries, you have the customer id, which is unique for the customers, but inside a report you want not display this key, because a business user does not care about it.
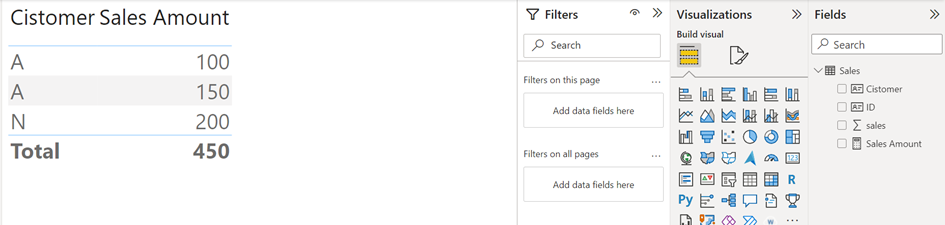
Okay, here I show some sample data – the customer A is two times inside the table, but they are two different identities, because we have different ID’s.
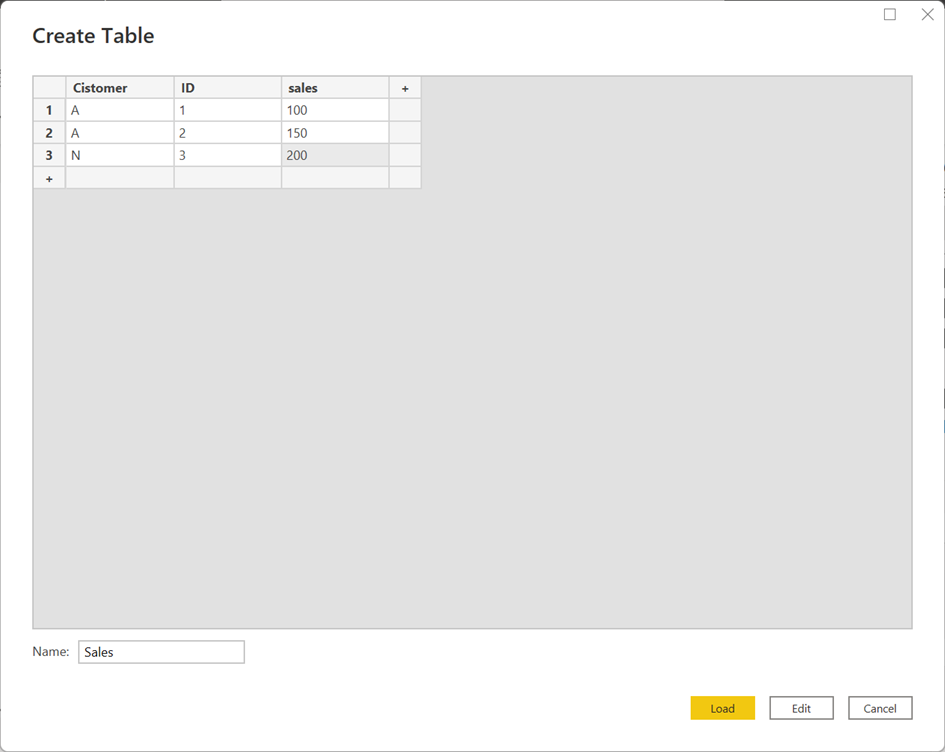
Now, when we built up a report without the ID, the sales amount for customer A will be summarizes, but this result is absolutely wrong!
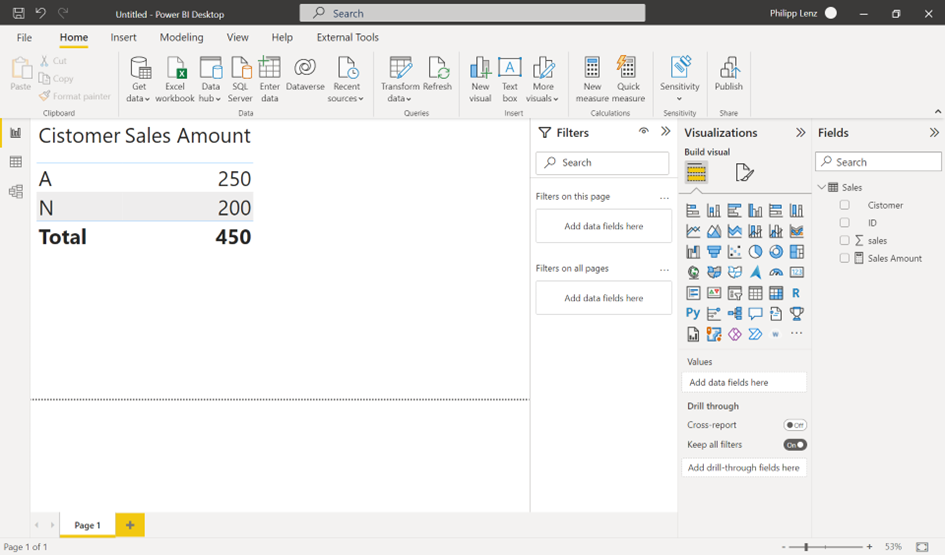
If we add the customer ID, it looks better, but again, mostly the business users do not like this layout.
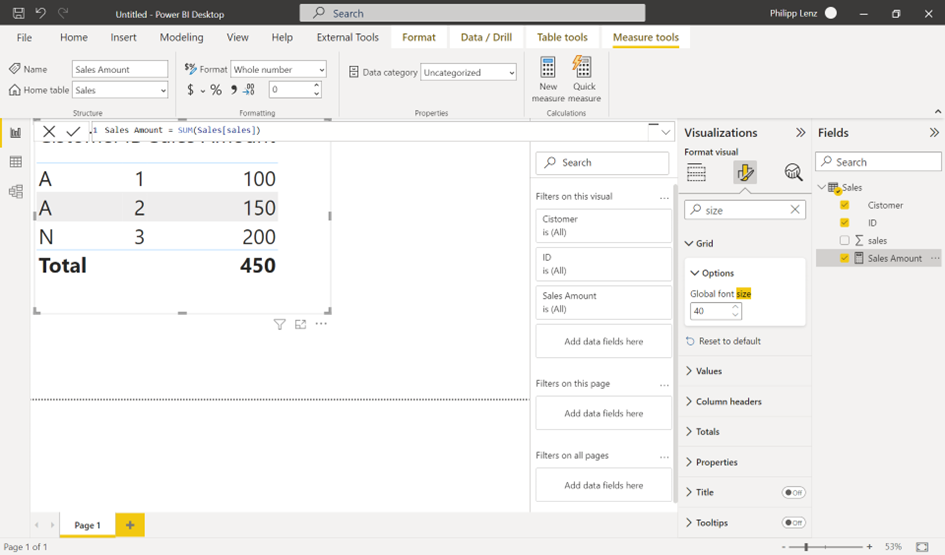
Now, we can configure our table to use for summarization with the customer’s name, to split it by the ID’s, so Power BI / Tabular uses the unique identifier, the ID.
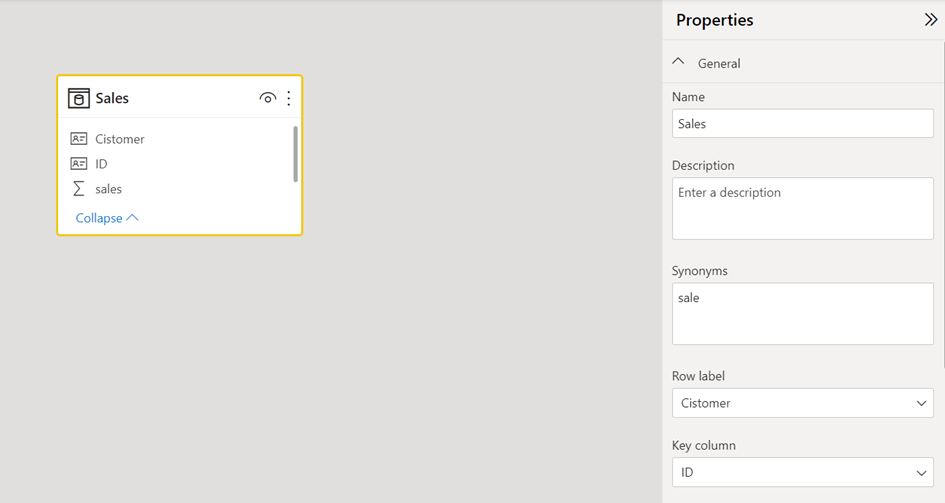
Now, the report without the ID looks fine.
If you have existing tables, and you configure this feature, sometimes it will nor work. To resolve it, remove the column from the visual and re-add it.